
作者在上一篇文章《高并发和高渲染是数字孪生落地的两大困境》中论述了高并发和高渲染质量的问题,评论起引发热议,作为非研发背景、不懂数字孪生技术的解决方案人员,着实吓了一跳。很多专业研发人员、技术人员留言评论,给了非常中肯的批评意见,本人一并接纳,好好学习和消化。
一、数字孪生空间数据分布式部署架构
通过浏览器访问的高并发(非客户端软件)通常有两种方式:WebGL和视频流(像素流)推送。本篇不讨论WebGL这种网页端JavaScript框架渲染技术,和分布式部署的关系不大,本处仅讨论视频流和像素流高并发的解决方案:分布式集群部署。
在数字孪生系统平台的建设过程中,三维引擎(3D引擎)的系统性能非常重要。而是否支持分布式集群架构,决定了是否能够同时解决高渲染质量和高并发访问的两大困境。
为了更好的解决高并发、高渲染质量,三维引擎需要支持模型数据存储的分布式集群架构,不同的数据可部署在不同的服务节点,由浏览器前端自动匹配从不同节点获取的模型数据,实现统一融合显示。如下图所示:
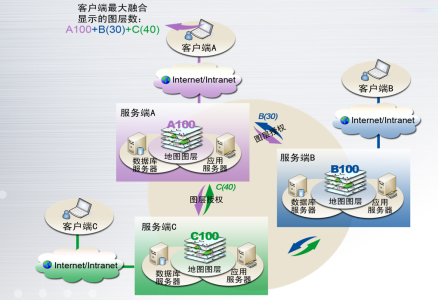
在上图中:
- 服务端A:包括数字孪生应用服务器、数据库服务器、地图图层(假定100个图层应用)。需要部署的软件平台包括数字孪生系统平台、3D引擎、操作系统、数据库、API接口等等,硬件配置包括应用服务器(可带CPU、可不带GPU)、数据库服务器。
- 服务端B和C:部署方式同服务端A一样。
- 以大学校园为例。服务端A、B、C可满足三个校区(假定为A、B、C三个校区)分别部署数字孪生校园平台,每个校区可以部署同一套系统也可以部署不同的系统,比如服务端A只能调用校区A的视频监控、录播系统视频信号,服务端B只能调用校区B,这样就可以减轻并发的压力,属于典型的分校区分布式部署。
客户端A、客户端B、客户端C采用一台计算机通过浏览器访问数字孪生平台的服务端。以客户端A访问为例,首先在分布式架构部署的情况下,渲染方式有两种:
- 服务端A云渲染:这种情况要求数字孪生应用服务器要配置专业的GPU显卡,渲染结果提供的是视频流,通常是采用H.264或H.265编码标准压缩的1080P分辨率的视频流,经过测试,目前单台服务器采用GPU显卡可以渲染1-8路视频流。这种模式对带宽的要求比较高,每路最少需要4Mbps的码流(推荐8M),这样的话8路视频流需要的带宽就是32Mbps甚至更多。如果超出8路渲染的视频流,则需要服务端B进行接管,超出16路视频流请求,则服务器C进行响应。这种分布式架构部署的数字孪生平台最大能响应的视频流服务(即云渲染)的路数为24路。在云渲染的情况下,对客户端A的访问终端没有限制(手机、平板、电脑均可,对专业GPU显卡也没有要求)。这种云渲染的并发数会限制到24路。
- 客户端A本地渲染:这种情况下,客户端A只能采用专业图形计算机进行访问,需要配置一块专业的GPU显卡(比如NVIDIA GeForce GTX 1080 Ti)。这块显卡通过后台的渲染程序采用像素流的方式进行渲染,像素流的渲染是不经过压缩的,可达到4K甚至更高的分辨率。如果显卡的配置足够高,就能够实现4×4K分辨率的输出,也就是能够满足指挥中心4块4K高清大屏拼接的显示,可实现高渲染质量的效果。在客户端本地像素流渲染的情况下,对服务端A、B、C并无显卡配置的要求,即服务器可以不用配置专业GPU显卡,仅提供数据推送服务。经过作者的测试和专业技术人员的探讨,服务器A最大能够提供500路“客户端A本地渲染”服务,三台服务器的分布式部署最多提供1500路的并发。这也就是作者在上篇文章中提到的为什么高并发和高渲染质量不能兼得的解释。当然不一定对,请大家批评指正。
- 视频流推送的分辨率为1080P(当然也可以是4K,但是带宽和GPU压力不允许,就比如说我们常见的HDMI线缆4K传输即使使用光纤线传输也不能超过100米)、像素流推送的分辨率为4×4K分辨率,所以我们认为后者为高渲染质量、前者为中等质量渲染。当然不管是视频流推送还是像素流推送,均支持在浏览器中访问、支持鼠标、键盘反向触控,即我们可以像操作电脑显示器一样的操作数字孪生平台。这里的视频流、像素流和B站的视频还是有很大区别的,B站的视频是事先生成的,而数字孪生的视频是实时渲染并支持反向触控的。
- 访问权限:客户端A在访问三台服务器的时候可以分配不同的权限,比如服务端A提供100个图层的权限、服务端B提供30个图层的权限、服务端C提供40个图层权限,这样就形成A(100)+B(30)+C(40)。这样我们就可以为不同的访问入口提供不同的服务,比如你可以调用A校区的监控信号但不能调用B校区和C校区的监控摄像机信号。同样也可以为客户端B、客户端C配置不同的图层权限。在数字孪生系统的建设中,可以建设几百个这样的图层提供各种各样的场景服务。
二、背景信息
1.什么是分布式架构?
分布式架构(Distributed Architecture)是分布式计算技术的应用和工具,成熟的技术包括J2EE, CORBA和.NET(DCOM),这些技术牵扯的内容非常广,相关的技术,相关的书籍也非常多。
(1)分布式计算技术的形成
CORBA (Common Object Request Broker Architecture)是在1992年由OMG(Open Management Group) 组织提出的。那时的分布式应用环境都采用Client/Server架构,CORBA的应用很大程度的提高了分布式应用软件的开发效率。
当时的另一种分布式系统开发工具是Microsoft的DCOM(Distributed Common Object Model)。Microsoft为了使在Windows平台上开发的各种应用软件产品的功能能够在运行时(Runtime)相互调用(比如在Microsoft Word中直接编辑Excel文件),实现了OLE(Linked and Embedded Object)技术,后来这个技术衍生为COM(Common Object Model)。
随着Internet的普及和网络服务(Web Services)的广泛应用, Browser/Server架构的模式逐渐体现出它的优势。于是,Sun公司在其Java技术的基础上推出了应用于B/S架构的J2EE的开发和应用平台;Microsoft也在其DCOM技术的基础上推出了主要面向B/S应用的.NET开发和应用平台。
(2)使用的协议
.NET中涵盖的DCOM技术和CORBA一样,在网络传输层都采用TCP/IP协议;也都有自己的IDL规范。所不同的是,在TCP/IP之上,CORBA采用GIOP/IIOP协议,所有CORBA服务器以IIOP通信,形成了ORB软件通道;J2EE的RMI曾经采用独立的通信协议,已经改为RMI/IIOP,体现了J2EE的开放性;DCOM也有自己的通信协议(TCP在135端口的服务),但微软没有公开这个协议的规范;同样,CORBA的IDL采用类C++的定义,是公开的规范;DCOM的IDL的文件虽然是文本形式的,微软没有正式公布它的规范,在使用中,.NET的IDL是由开发工具生成的。
(3)应用的环境
关于.NET,比尔盖茨这样说:“简单地说,.NET是以微软的各种产品为开发工具和应用平台, 实现基于XML的网络服务。”由此也可以看出,.NET在Microsoft的世界里功能强大,但对于Unix和Linux这些在服务器市场占主要份额的系统,.NET显得束手无策。
因此,J2EE显示了它跨平台的优势,为网络服务商提供了很好的面向前端(front-end)的开发和应用平台,随着网络服务进一步广泛应用和服务集成度的提高,在网络服务提供商的后台会形成越来越庞大的分布式计算环境,CORBA模块结构更适合后台(back-end)的多种服务,例如网络服务的计费程序等。因此可以看出,J2EE和CORBA技术在网络服务(Web Services)这片蓝天下, 各自有自己的海洋和陆地。如果在前端(front-end)使用了.NET开发平台,那么在后端(back-end)的分布式结构中,DCOM就是理想的选择。
J2EE是纯Java技术,很多测试显示RMI(Java)服务器的响应速度远远低于非Java的CORBA服务器。因此,在一些对数据处理速度和响应时间要求较高的系统开发中,要对RMI和CORBA的性能进行测试对比后再做选择。
更多的背景信息,大家可以百度自行查询。
2.什么是集群(Cluster)?
集群(cluster)是一种较新的技术,通过集群技术,可以在付出较低成本的情况下获得在性能、可靠性、灵活性方面的相对较高的收益,其任务调度则是集群系统中的核心技术。
集群是一组相互独立的、通过高速网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管理。一个客户与集群相互作用时,集群像是一个独立的服务器。集群配置是用于提高可用性和可缩放性。
一般可以分为以下几种:
- 容错机;
- 基于系统镜像的双机系统;
- 基于系统切换的双机系统;
- 基于应用程序切换的集群;
- 基于并行计算的集群;
- 基于动态负载均衡的集群。
根据典型的集群体系结构,集群中涉及到的关键技术可以归属于四个层次:
- 网络层:网络互联结构、通信协议、信号技术等。
- 节点机及操作系统层高性能客户机、分层或基于微内核的操作系统等。
- 集群系统管理层:资源管理、资源调度、负载平衡、并行IPO、安全等。
- 应用层:并行程序开发环境、串行应用、并行应用等。集群技术是以上四个层次的有机结合,所有的相关技术虽然解决的问题不同,但都有其不可或缺的重要性。
更多的集群背景知识,请自行百度,作者就不班门弄斧了。